먼저 이글의 목차입니다.
1. 티베로 쿼리 실행계획(Cpu, Cost 등) 조회하는 방법.
2. 실행계획을 기반으로 쿼리 튜닝하는 방법
1. 티베로 쿼리 실행계획(Cpu, Cost 등) 조회하는 방법.
DB 쿼리 실행계획이란? 무엇일까를 먼저 간단히 설명드리겠습니다.
DB 쿼리 실행계획이란?
말그대로 DBMS에서 특정 쿼리를 실행할 때, 어떤 동작을 할 것인지, 계획을 세우는 것을 말합니다.

위와 같이 하나의 쿼리에서 Join, Table Access 동작 등의 계획을 나타냅니다.
아래와 같이 버튼을 누르면 티베로 스튜디오에서 간단하게 실행계획을 조회할 수 있습니다.

둘중 아무거나 눌러도 됩니다.
Cpu 사용률, Cost 사용률을 조회하려면 아래와 같은 쿼리로 조회하면 됩니다.
SELECT SUBSTRB(TO_CHAR(ID), 1, 3) || LPAD(' ', LEVEL * 2) || UPPER(OPERATION) ||
DECODE(OBJECT_NAME, NULL, NULL, ': '||OBJECT_NAME) || ' (Cost:' || COST ||
', %%CPU:' || DECODE(COST, 0, 0, TRUNC((COST - IO_COST) / COST * 100)) ||
', Rows:' || CARDINALITY || ') ' ||
DECODE(PSTART, '', '', '(PS:' || PSTART || ', PE:' || PEND || ')') AS "Execution Plan"
FROM (SELECT * FROM V$SQL_PLAN WHERE SQL_ID = 'SQL ID로 조회')
START WITH DEPTH = 1
CONNECT BY PRIOR ID = PARENT_ID AND PRIOR SQL_ID = SQL_ID
ORDER SIBLINGS BY POSITION;
sql id는 위에서 조회한 실행 계획으로 조회하셔도 되고, 아래의 쿼리로 조회가 가능합니다.
select sql_id from V$SQLTEXT where upper(sql_text) like '%쿼리 내용(예를들어 select * from Test)%';
2. 실행계획을 기반으로 쿼리 튜닝하는 방법
먼저 이슈사항으로는 조회 쿼리 한번에 15초 ~ 16초가 걸려서 너무 느리다! 였습니다.
조회하는 테이블의 데이터가 많긴하지만, 조회 쿼리가 15초가 걸린다는건 좀 문제가 있어보여, 쿼리 튜닝을 시작했습니다.
먼저 문제가 있어 보이는 쿼리를 따로 떼어 내어 분석을 해보겠습니다.
테이블 구성
| 테이블명 | Row 개수 |
| TEST_A | 약 220만 건 |
| TEST_B | 약 20만건 |
| TEST_C | 약 2천건 |
| TEST_D | 약 2천건 |
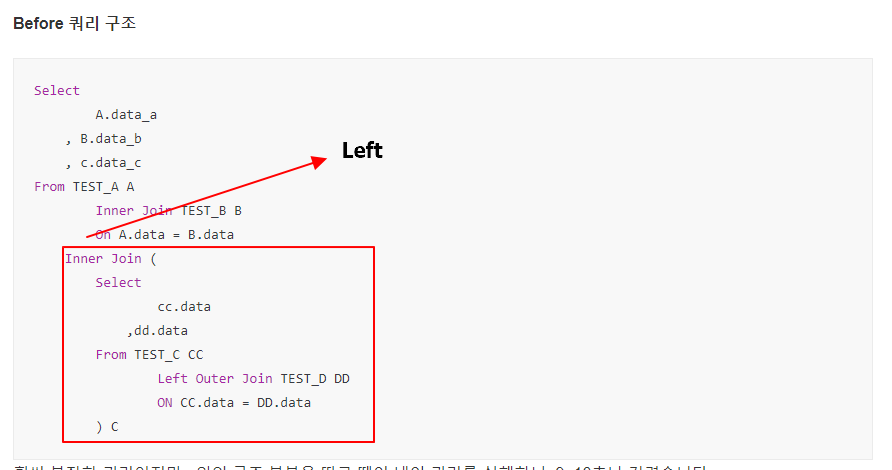
Before 쿼리 구조
Select
A.data_a
, B.data_b
, c.data_c
From TEST_A A
Inner Join TEST_B B
On A.data = B.data
Inner Join (
Select
cc.data
,dd.data
From TEST_C CC
Left Outer Join TEST_D DD
ON CC.data = DD.data
) C
On c.data = a.data훨씬 복잡한 쿼리이지만, 위의 구조 부분을 따로 떼어 내어 쿼리를 실행하니, 9~10초나 걸렸습니다.
실행계획은 아래와 같습니다.

TEST_A가 데이터가 가장 많은데, 맨 마지막에 FULL 스캔을 한다고 되어 있습니다.
변경
아래와 같이 서브쿼리 쪽 inner 조인을 left 조인으로 변경하니까
실행계획은 아래와 같이 바뀌었구요.

cost는 거의 3배가 증가 했지만, 응답속도는 15배가 줄어서 0.1초만에 조회가 됩니다.
이유를 추측해보자면, 서브쿼리 (C,D 테이블 OUTER JOIN)을 TEST_A 테이블이 관여를 하냐 안하냐로 갈리는 것 같습니다.
이전 쿼리에서
TEST_A 테이블은 데이터가 220만 건으로 엄청나게 많습니다. 하지만 서브쿼리의 데이터들은 그에 비해 데이터가 많이 없지만, 서브쿼리로 인해 LEFT OUTER 조인이 걸려 있기 때문에 INNER JOIN 조건으로 TEST_A 테이블과 모두 매칭해보기 때문에 NESTED LOOP가 도는 것 같습니다.
이후에는 LEFT 조인으로 변경 했기 떄문에, TEST_A 테이블이 서브 쿼리안의 조인에 관여를 하지 않고, 서브 쿼리가 실행된뒤, TEST_A,TEST_B의 INNER JOIN 테이블에 데이터를 매칭하는 형식이기 때문에 빨라진 것 같습니다.
긴글 읽어 주셔서 감사합니다.
더 궁금하신 사항은 댓글로 문의해주시면 빠르게 답변드리겠습니다.
'데이터 베이스' 카테고리의 다른 글
| MSSQL 쿼리 실행계획 / 튜닝 팁 (0) | 2024.11.12 |
|---|---|
| 프로그램 구조 변경으로 DB서버 점유율 낮춤. (db 호출 구조 변경) (0) | 2024.10.04 |

댓글